//
Subscribe to the Tabnine newsletter
//
Get news and updates about AI, software development, and more.

Using ChatGPT in an organization presents several security challenges. One of the primary concerns is data privacy. ChatGPT processes and stores user inputs, which might include sensitive or proprietary information. Without stringent data handling and storage policies, this data could be vulnerable to unauthorized access or breaches. Organizations must ensure that they comply with data protection regulations, such as GDPR or CCPA, and implement measures like data anonymization and encryption to safeguard user information.
Another significant risk is the potential for misuse by malicious actors. ChatGPT can generate code, scripts, or even responses that could be used for phishing attacks or other malicious activities if prompted inappropriately. Although OpenAI has implemented safety measures to prevent harmful outputs, these filters are not foolproof and can sometimes be bypassed.
To mitigate these risks, organizations should implement strict access controls, ensuring that only authorized personnel can use ChatGPT for specific tasks. Regular monitoring and auditing of AI-generated outputs are also crucial to detect and prevent any potential misuse. Comprehensive training programs should be established to educate users about the ethical and secure use of AI tools like ChatGPT.
This is part of a series of articles about ChatGPT alternatives.
Despite its popularity, there are several security risks associated with using ChatGPT.
Unauthorized access to ChatGPT accounts can lead to misuse of the service, such as generating harmful or misleading information. Attackers might also gain access to any stored personal or corporate data linked with the user’s account. Thus, it’s important to implement robust authentication and account security practices.
To illustrate the risk, a recent vulnerability discovered in ChatGPT allowed attackers to take over any user’s account with a single click, exploiting a web cache deception flaw. By manipulating the caching mechanisms, attackers could deceive the server into caching sensitive information, such as session tokens. The attacker created a path to the session endpoint and sent the link to the victim. When the victim clicked the link, the response was cached, enabling the attacker to harvest the victim’s credentials and take over their account.
This vulnerability allowed attackers to access sensitive user information, such as names, email addresses, and access tokens, which were retrieved from OpenAI’s API. With this information, attackers could perform unauthorized actions, posing severe risks to user privacy and security. Organizations should implement strong security measures, such as role-based access controls and regular audits, to mitigate such risks.
When interacting with large language models (LLMs) like ChatGPT, users often input sensitive data without considering the potential exposure. This information can be inadvertently stored or misused, leading to privacy concerns and compliance issues with data protection laws. Additionally, the model might generate outputs that unintentionally include this sensitive data. Another risk is that personal data could be used to train the LLM.
According to Netskope’s Threat Report on AI in the Enterprise, a study of large enterprises found that out of 10,000 average enterprise users, more than 180 incidents were recorded of sensitive company data being posted to ChatGPT. Out of those incidents, 22 users reported posting a total of 158 proprietary source code snippets to ChatGPT.
To mitigate these risks, developers and organizations must implement stringent data-handling measures and educate users about the information they should avoid sharing. Techniques that anonymize user data can help minimize the direct association of inputs with individual identities.
Privacy breaches occur when confidential information is exposed to unauthorized parties, often leading to severe consequences for both users and service providers. With AI models like ChatGPT, data leaks can arise from vulnerabilities in the system or unsafe data handling practices.
Security and AI researchers have discovered multiple vulnerabilities and prompt injection attacks that caused ChatGPT to reveal its training data. For example, Wired reported on research by Google DeepMind in late 2023, which caused ChatGPT to divulge several megabytes of its training data when asked to repeat the same word endlessly. (You can read the full paper.) Although OpenAI has mitigated this and other vulnerabilities, new ones are constantly being discovered.
This highlights the risks of sharing sensitive or proprietary information with ChatGPT. Organizations should take into account that LLMs can be induced to “regurgitate” their training data and take measures to reduce risk, by educating employees and implementing policies that limit the sensitive data that can be shared with the tool.
API attacks have become increasingly prevalent in enterprises, and API security is becoming a major focus of cybersecurity teams. Cybercriminals are also leveraging advanced technologies like generative AI to discover and exploit API vulnerabilities.
Analysts at Forrester predict that attackers could use tools like ChatGPT to analyze API documentation, aggregate information, and craft sophisticated queries aimed at identifying and exploiting weaknesses. This approach can significantly reduce the time and effort needed to find API vulnerabilities, making it easier for attackers to launch successful attacks.
To mitigate these risks, organizations should implement robust API security measures. This includes conducting regular security assessments, employing rate limiting to prevent abuse, and ensuring secure communication protocols like HTTPS. Additionally, developers should follow best practices for API design and security, such as authentication, authorization, and input validation to protect against potential threats.
When using ChatGPT, there are several intellectual property (IP) concerns to consider. ChatGPT generates text based on vast amounts of pre-existing information, some of which may be subject to copyright. This can lead to the unintentional inclusion of copyrighted material in the output, raising legal issues regarding the ownership and use of generated content. For organizations, this means that outputs could inadvertently violate IP laws, exposing them to potential legal challenges.
Organizations should implement strict policies and guidelines for using AI-generated content, ensuring that all outputs are thoroughly reviewed for potential IP issues. Additionally, incorporating tools that automatically check for copyrighted material can help mitigate these risks. Users should also be educated on the importance of respecting IP rights and the legal implications of misuse.
Another significant risk is compliance with open source licenses when using ChatGPT-generated code. If ChatGPT generates code snippets, it’s possible that these snippets could contain code that’s subject to open source licenses like GPL, which require the disclosure of source code when used in proprietary projects. This can create legal complications if the generated code is integrated into products without proper adherence to the license terms.
To address this, organizations should establish clear guidelines for using AI-generated code, including processes for reviewing and verifying the origin of the code. Employing tools that track and manage open source components can also help ensure compliance. It’s crucial to train developers on the legal obligations associated with different open source licenses to prevent inadvertent violations.
The introduction of ChatGPT plugins has expanded the tool’s functionality, allowing users to integrate third-party services. Although OpenAI reviews these plugins for compliance with content, brand, and security policies, there are inherent risks. Data sent to these third parties is subject to its own processing policies, which may not align with OpenAI’s standards. This opens potential vulnerabilities where cybercriminals could exploit these integrations to access end user data.
One of the main risks associated with plugins is prompt injection, where malicious inputs could manipulate the plugin to expose sensitive data or perform unintended actions. To mitigate these risks, users should be cautious about the plugins they install. It’s crucial to read the data policies of these third-party services and ensure only necessary plugins are active during a session. This approach limits data exposure and reduces the risk that sensitive information could be accessed through unused plugins.
Data retention involves storing users’ conversational data, which might contain personal information. This holds legal and ethical implications regarding user privacy and data security. If not managed properly, retained data can be vulnerable to breaches and misuse.
For example, Spiceworks reported on two instances where ChatGPT accounts were compromised by threat actors. One instance occurred when an attacker using a spoofed location managed to extract sensitive data, including account usernames, passwords, and data from other users’ accounts. Another was an accidental leak of company secrets by Samsung employees, which led to a company-wide ban on the use of ChatGPT.
Mounting privacy concerns led the Italian privacy regulator to briefly ban ChatGPT in Italy in mid-2023. In early 2024, the same regulator charged OpenAI with a breach of the General Data Protection Regulation (GDPR) related to the mass collection of user data used to train ChatGPT’s algorithms. Organizations complying with privacy regulations like GDPR, CCPA, or HIPAA should take note and consider the compliance risk of tools like ChatGPT.
ChatGPT may generate inaccurate or misleading content, especially when prompted with questions outside its training data or containing factual inaccuracies. This could lead to decisions based on incorrect information, especially in sensitive areas such as medical advice or legal issues.
A particular area of concern is code generation. Code snippets using nonsecure coding practices or including security vulnerabilities could have catastrophic consequences if used as-is in a software project. In an academic paper (Khoury et al., 2023) researchers asked ChatGPT to write 21 software programs and evaluated their security, finding that they “fell way below even minimal standards of secure coding.”
When the researchers asked the chatbot whether specific vulnerabilities existed in the code, it acknowledged them and tried to improve the code. But many users may not be aware of vulnerabilities in the code they generate with tools like ChatGPT.
There’s a risk that when ChatGPT is prompted inappropriately, it could generate malicious code or instructions that could assist in cyberattacks. This possibility raises significant security concerns, particularly in scenarios where AI is accessed by users with malicious intent.
According to a study by CyberArk, although OpenAI has implemented safety filters to prevent the creation of harmful code, these filters can sometimes be circumvented. For example, when prompted with specific techniques from the MITRE ATT&CK framework, ChatGPT was able to generate code snippets for malicious activities like credential harvesting from web browsers.
The study revealed that with slight modifications in prompts, such as altering the phrasing of the request, the AI could produce functional code snippets that could be assembled into a complete malware script. This ability to generate and modify malicious code poses a severe threat, as it can simplify the process for cybercriminals to develop sophisticated malware. Organizations must continuously monitor and assess the outputs of AI tools like ChatGPT to ensure they aren’t used for illicit purposes.
When generating code, AI models like ChatGPT may occasionally recommend software libraries or packages that don’t actually exist. This issue arises from a phenomenon known as AI hallucination, where the model generates plausible but incorrect information based on its training data. Attackers can exploit this by creating malicious packages with the names of these nonexistent libraries.
For example, an attacker might publish a malicious package under the name of a nonexistent library recommended by ChatGPT. Unsuspecting users might then install and use these malicious packages, leading to potential security breaches. To mitigate this risk, users should verify the existence and legitimacy of recommended packages through trusted sources before installation. Additionally, organizations should implement security measures to monitor and prevent the use of unverified software libraries.
Related content: Will ChatGPT Replace Programmers?
There are several measures that can help make ChatGPT safer to use.
Access controls help protect sensitive systems and data from unauthorized access. By implementing role-based access control (RBAC) systems, organizations can ensure that only authorized personnel have access to specific levels of information based on their roles.
In addition to RBAC, it’s important to conduct regular reviews of access rights and promptly revoke access for terminated or transferred employees. These controls ensure compliance and help minimize internal and external security risks.
Continuous monitoring and auditing of systems using ChatGPT help in the early detection of unusual activity that might indicate a security breach. This includes tracking and logging accesses and changes to the system, which can be analyzed for signs of unauthorized or malicious activity.
Regular audits are also crucial in ensuring that the security measures in place are effective and adhere to the latest security standards and compliance requirements.
Routine checks for biases and fairness in AI applications are necessary to ensure that the responses generated by ChatGPT are objective and nondiscriminatory. This involves regularly analyzing the model’s output and retraining the system with corrected or additional data to eliminate identified biases.
These checks help in building AI systems that operate ethically and foster trust and inclusivity. Ensuring fairness in AI responses benefits the users, but it also enhances the credibility and acceptability of the technology in various applications.
When integrating ChatGPT with other systems via APIs, it’s crucial to secure these connections to prevent data breaches and unauthorized access. To enhance API security, organizations should enforce the use of secure communication protocols such as HTTPS to encrypt data in transit. Additionally, API keys should be managed carefully; they must not be hard-coded into applications but rather stored securely using environment variables or dedicated secrets management tools.
API rate limiting is also important to mitigate the risk of denial-of-service attacks and to manage the load on services. Regular security reviews and vulnerability assessments should be performed on APIs to ensure that they don’t have any security flaws that could be exploited by cyberattackers.
Educating users on the proper use of ChatGPT is essential to mitigate security risks. Training should include awareness of the types of information that should not be shared with AI systems, recognizing phishing attempts, and understanding the importance of maintaining strong, unique passwords for accessing AI services.
Organizations should also educate employees on the implications of data privacy laws and compliance requirements when using AI tools like ChatGPT. Regular updates on security practices and emerging threats can help keep all users informed and vigilant against potential cyberthreats. This proactive approach to user education will not only secure the organizational data, but also empower users to utilize AI tools responsibly and effectively.
Read more about AI for software development in our guide for AI coding tools.
Although the best practices above can help mitigate some risks, there are several reasons organizations should seriously consider the use of these tools, especially for sensitive or business-critical tasks.
When using tools like ChatGPT for tasks like content creation or coding, you should be aware that they’re trained on the entire internet. When it comes to code, this includes code that may be proprietary or subject to nonpermissive open source licenses, which can create legal risks for your organization.
Practical Law Journal recently covered the legal risks of using ChatGPT. One case highlighting this issue involved a company that used ChatGPT to generate code for a proprietary software project. Upon a compliance review, they discovered that portions of the generated code were identical to code from a GPL-licensed project, necessitating the release of their proprietary code under the same license, which wasn’t their intention.
In another instance, a company found that content generated by ChatGPT included text fragments from a copyrighted book. This raised potential copyright infringement issues, as the generated text was used in a commercial setting without proper attribution or license.
ChatGPT experienced many instances in which private user data leaked or was compromised by attackers. This raises concerns for organizations managing sensitive or proprietary information. It’s important to weigh the benefits of using ChatGPT with the potential for exposure of private or sensitive data.
The new Team and Enterprise editions of ChatGPT do promise not to use user data for training; however, it’s important to carefully read the fine text to understand the scope of these guarantees. In addition, the fact that ChatGPT stores customer data as part of its cloud service raises inherent risks that have led to multiple security breaches during the service’s short history.
Organizations with strict privacy and security requirements typically prefer to deploy tools in a virtual private cloud (VPC) or on-premises. This option is currently not offered by ChatGPT. By using ChatGPT, you’re effectively using a multitenant SaaS solution, with your data stored alongside the data of millions of other users on the same public servers.
Tabnine is the AI code assistant that you control. It helps development teams of every size accelerate and simplify the software development life cycle without sacrificing privacy and security.
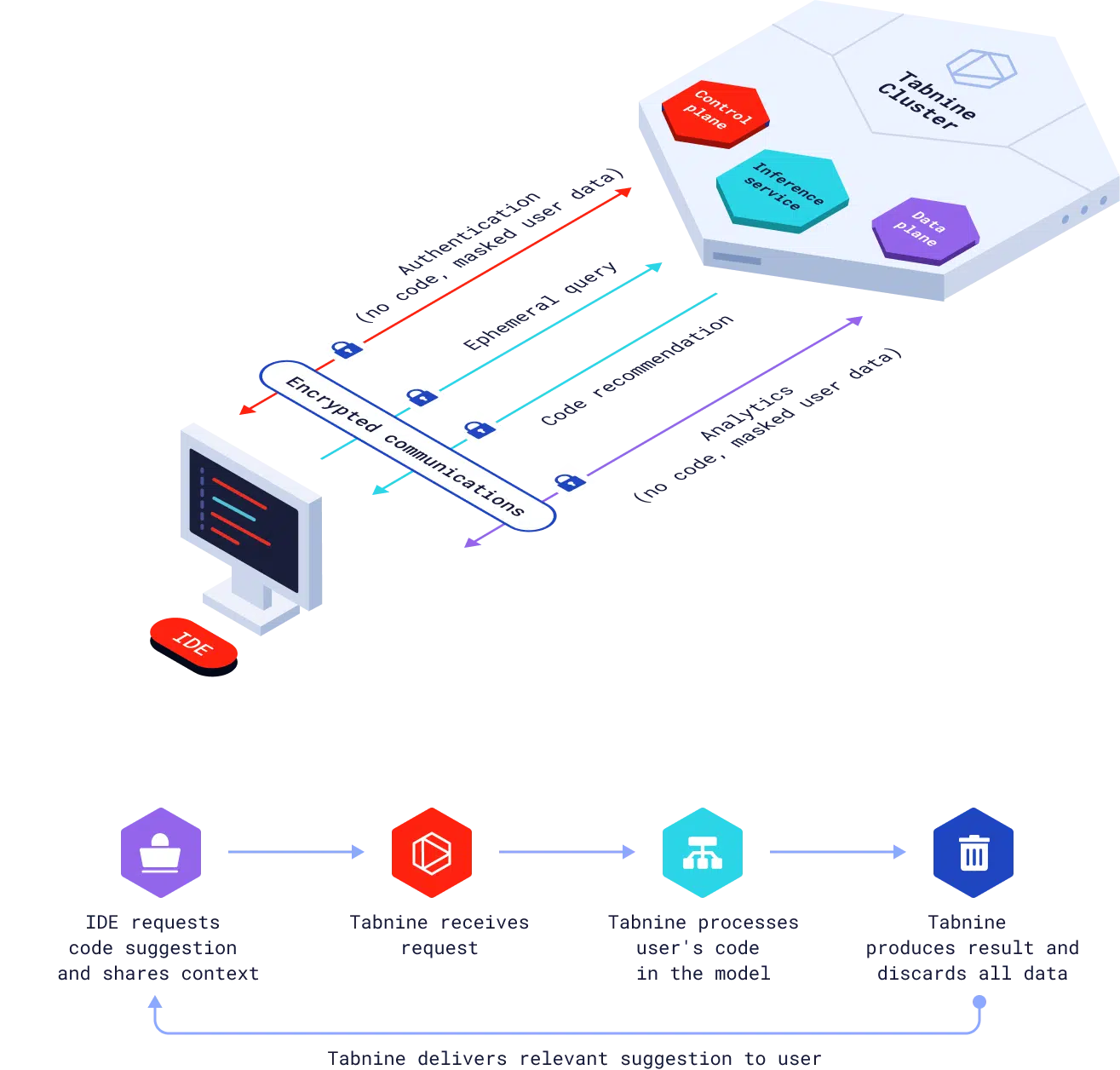
Here’s how Tabnine puts you in total control of your data, ensuring the privacy of your code and your engineering team’s activities:
Your code is never stored.
Tabnine provides end-to-end encryption with private keys for each customer instance, transport layer security, and uses ephemeral processing to deliver a policy of zero code retention. We also provide continuous monitoring and audits.
Your code never trains our general models.
Every Tabnine customer gets their own model and training. Your private data only affects the performance of your unique model. Your code never leaves your codebase and is never shared with other customers or Tabnine infrastructure.
You control the context Tabnine uses.
You choose the level of personalization and contextual awareness you want to provide to your Tabnine model. You can fully control access for Tabnine to local context in your workspace, and define admin permissions for Tabnine to access your organizational repositories. You can segregate connections by teams and have the option to fine-tune your models for different projects and teams using your own training data.
Your code or usage data is never shared.
We won’t write case studies about your performance data in Tabnine without your permission, and we don’t store or share your code or usage data with third parties.
You control where you deploy.
Tabnine is the most secure and private AI code assistant. You can deploy our models VPC or air-gapped on-premises, and we have partnerships with major cloud providers and hardware manufacturers so we can help you with sourcing your infrastructure.
Explore recent posts
//Explore recent posts
//
6 -min read

2 -min read

3 -min read

More Guides
//2 -min read
2 -min read
2 -min read