{kind=link}
//
Subscribe to the Tabnine newsletter
//
Get news and updates about AI, software development, and more.

Concerns around copyright and license compliance are still keeping many large organizations from wide-scale adoption of generative AI tools. In recent studies, as many as one-third of CIOs cite these concerns. With multiple lawsuits still looming over whether or not LLM providers have the right to train on content and code without the explicit permission of their creators, it’s no surprise that many companies continue to seek models that can guarantee they won’t be subject to future litigation.
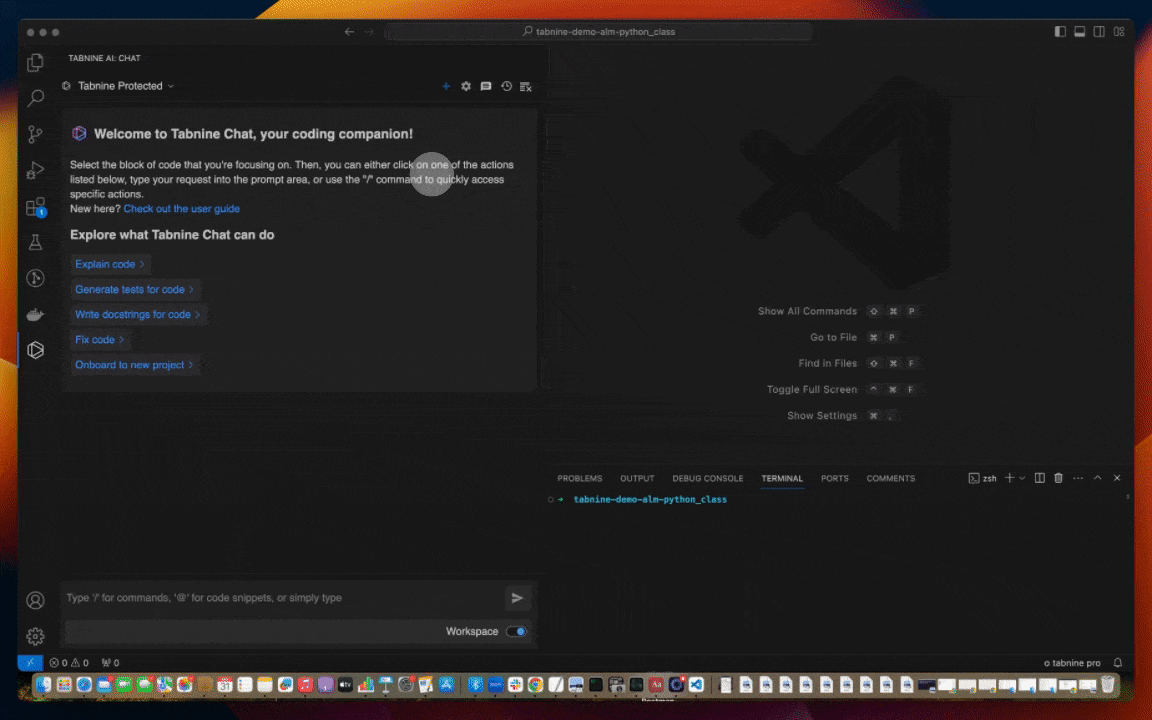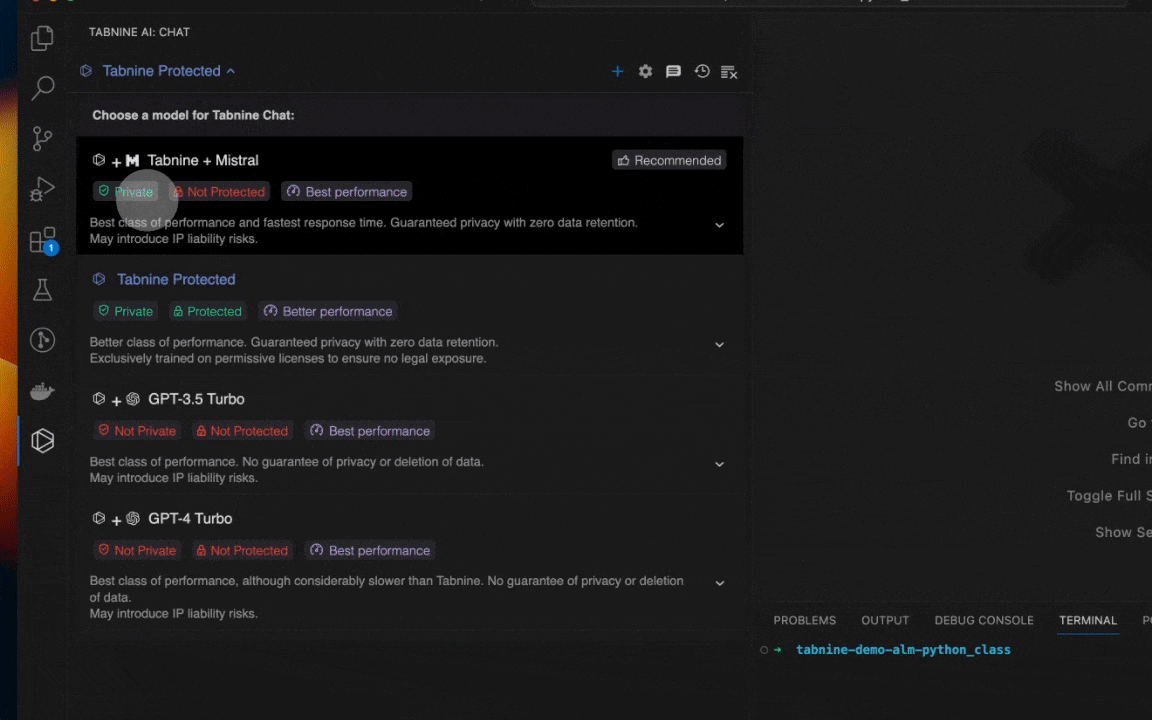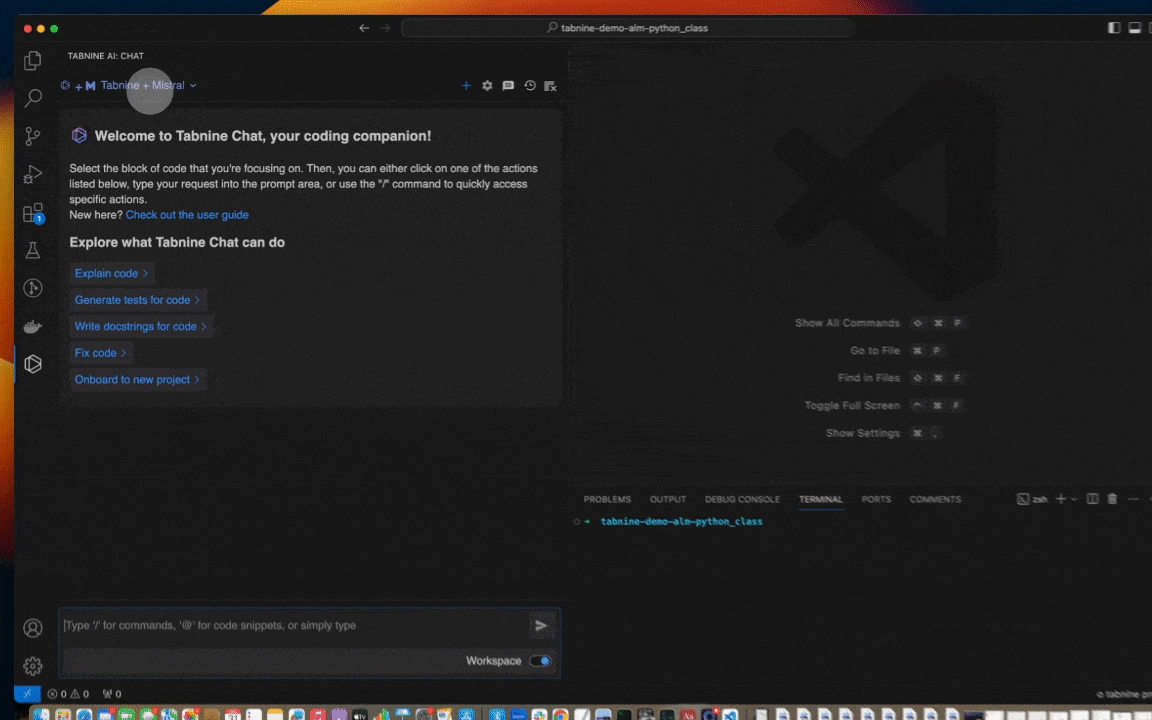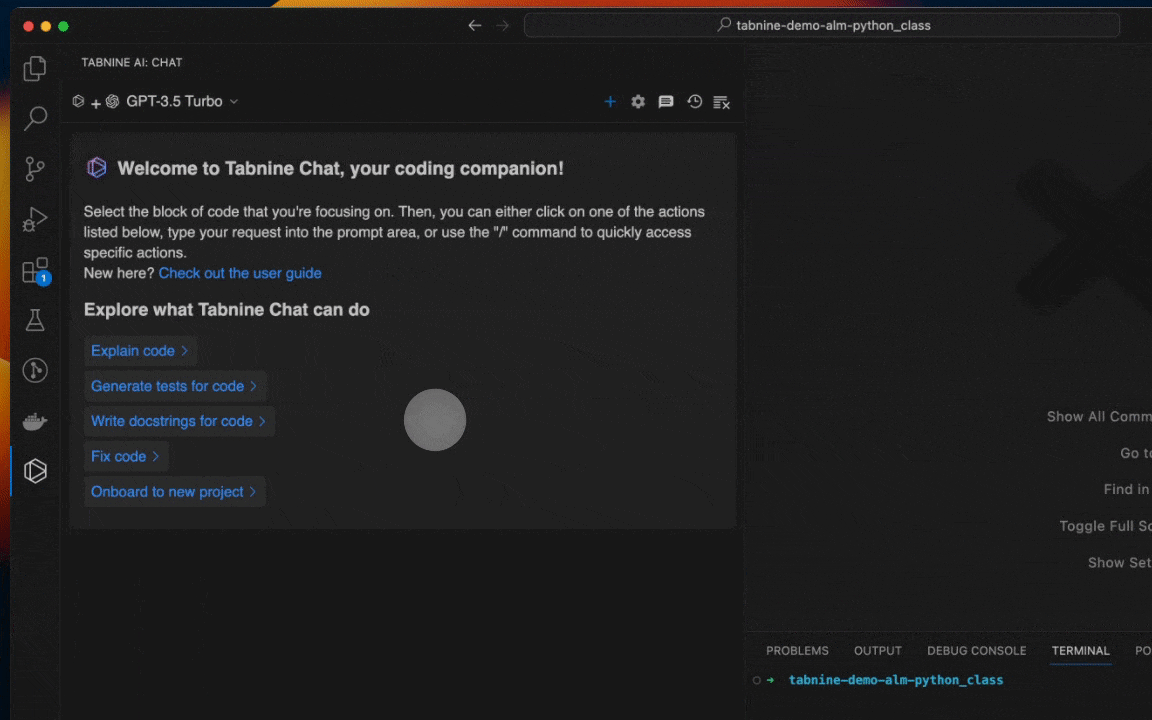
From the earliest days of Tabnine, we’ve offered our customers a variety of proprietary models trained on a curated set of high-quality, permissively licensed code. The pinnacle of this came with the launch of Tabnine’s chat platform last year, which came powered by the Tabnine Protected model. That model was trained exclusively on code that not only represented the best training data, but was also freely available for anyone to use, thus eliminating any potential legal liability. Even with the availability of a broad variety of models to underpin the Tabnine platform, our Protected model remains the primary choice of a significant portion of our customers.
Historically, limiting the training data meant accepting lower quality performance than the models trained without those restrictions. As of today, that trade-off has been virtually eliminated.
We’re excited to announce that we’ve created an entirely new version of Tabnine Protected, delivering significantly higher performance for teams that require a model trained exclusively on permissively licensed code. The new model, Tabnine Protected 2, not only outperforms its predecessor, but our internal evaluations demonstrate that it delivers performance that exceeds GPT-3.5 Turbo and a variety of other purpose-built software development LLMs. And these results are not restricted to the lab; Tabnine Protected 2 has demonstrated strong performance gains for our customers in real-world use cases.
Like its predecessor, the new model is purpose-built for software development teams looking for a model trained exclusively on code that’s available to use without license restrictions. This model lives alongside a variety of other LLMs that our customers can choose to underpin our AI agents and chat platform. Tabnine Protected 2 is fully private and protects our customers from any potential risks from the ongoing litigation around the use of third-party code for model training.
With Tabnine’s innovation, sensitive engineering teams now can see comparable performance to the top-tier models without having to deviate from their corporate standards.
In creating Tabnine Protected 2, we not only trained the model on a larger corpus of code (as would be expected), but we also expanded the context window to improve the quality of what is generated as measured by what the developer would expect.
Tabnine Protected 2 allows us to leverage context through retrieval-augmented generation (RAG) more effectively and thus has a better and more nuanced understanding of the user’s intentions and what they would find acceptable. As a result of using RAG, Tabnine interprets the user prompts more precisely and provides results that are more relevant and personalized. Additionally, the Tabnine Protected 2 model supports more than 600 programming languages and frameworks — a dramatic improvement over its predecessor that supported 80+ languages.
To quantify the improved performance of Tabnine Protected 2, our engineering team used numerous techniques to evaluate the performance of the new model, some of which are summarized below.
To evaluate the performance of each of the models, we used a consistent set of questions with each (posed through Tabnine Chat) and evaluated the output using another, distinct LLM (GPT-4).
Each of the models was asked the same set of questions and the generated responses were evaluated by GPT-4 for the following criteria:
The LLM was used to assign a score to each response and then we aggregated the scores to produce a final score for each model. Higher scores indicate stronger model performance in relevance, coherence, accuracy, completeness, and code correctness; lower scores indicate weaker performance. This approach is effective as it offers consistency, scalability, and objective assessment of the models.
In addition, our evaluation assessed interactions with chat with an increasing degree of available context to share:
As seen in the graph below, Tabnine Protected 2 not only provides a significant performance improvement over its predecessor, but also delivers results that are on par with a common benchmark, the larger and more extensively trained GPT-3.5 Turbo.

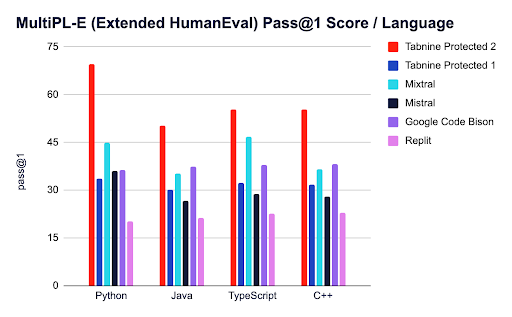
We also evaluated the model performance by leveraging the HumanEval and MultiPL-E benchmarks, popular benchmarks that check how well a model understands a programming problem and generates code that is both syntactically correct (i.e., code that adheres to the syntax of a programming language) and semantically correct. Since the HumanEval benchmark is limited to Python programming problems, we extended it with the MultiPL-E benchmark to include 17 other commonly used programming languages, such as Java, TypeScript, C++.
For each model, we determined the pass@1 score, which indicates the ability of the model to generate a correct answer in the first attempt. The higher the pass@1 score, the greater the probability of producing a correct answer in the first attempt. The pass@1 score is a crucial metric because it’s a good indicator of users getting immediate value from Tabnine in the real world.
The graph below shows the accuracy of code generated for some of the popular programming languages. Similar to the previous benchmark, this one also shows the remarkable performance delivered by the Tabnine Protected 2 model.
In addition to conducting internal benchmarks, we’ve also tested the Tabnine Protected 2 model to evaluate how often code recommendations are accepted relative to other models. We completed this test among a subset of our customers in real-world situations. (Note: They’ve permitted us to use their data for these purposes.)
As shown in the image below, when using the Tabnine Protected 2 model, there’s been a step change in the consumption rate of what is generated, indicating that users are accepting output (e.g., inserting results from code creation, copying results for tests, etc.) at a considerably higher rate. Tabnine Protected 2 now creates materials that are accepted at a higher rate than Mistral and GPT-3.5, the latter of which was trained on a massive, unrestricted corpus of code and was considered the best in the world only a short while ago.

As mentioned above, Tabnine Protected 2 is trained exclusively on permissively licensed code. This ensures that when using this model, the recommendations never match proprietary code and removes any concerns around legal risks associated with accepting the code suggestions. We also offer IP indemnification to enterprise customers to ensure peace of mind.
In addition, Tabnine Protected 2 model is a fully private model and can be deployed on any environment our customers choose (on-premises, on VPC, or via SaaS) — including in air-gapped environments. Tabnine always commits to zero data retention; we don’t store customer code, we don’t share customer code or usage data with third parties, and we never use customer code to train our public models.
There’s no additional cost to use Tabnine Protected 2 and all Tabnine users have access to the new model. Please make sure to update your IDE plugin to see the newest model.
Tabnine also continues to allow you to switch the LLM that powers our AI software development tools in real time. If you work on a variety of projects with different requirements for license compliance, you can move between Tabnine Protected 2 and the current top-performing models like Cohere and GPT-4o instantly. Tabnine is proud to be the only AI code assistant that puts you firmly in control.
Check out our Docs to learn more about this new model. If you’re not yet a customer, you can sign up for Tabnine Pro today — it’s free for 90 days or contact us to learn more.
Explore recent posts
//Explore recent posts
//18 -min read

3 -min read

6 -min read

More Announcements
//3 -min read
4 -min read
3 -min read