//
Subscribe to the Tabnine newsletter
//
Get news and updates about AI, software development, and more.

Tabnine now has over a million users and over 500k active monthly users. As a company we cherish the opportunity to work with some of our best users to understand how they interact with Tabnine. Adding to these priceless conversations is the data we gather from our users that choose to share with us for the benefit of product development.
One of the most fascinating data points is how some users really use Tabnine in a deep, deep way. These users have more than 30% of their code generated by Tabnine. On the other end of the spectrum there are users that really don’t find much value in our product. But why these two groups? Controlling the data for language and total usage uncovers some interesting observations. While a majority of our customers see 10-20% of their code generated by Tabnine the ends of the distribution have quite the Marmite characteristics.
Looking into this a bit deeper and doing observational sessions with new and experienced users we have found that there is a defining characteristic that makes Tabnine really shine. In this article we will discuss what we found and how this has helped us craft a simple set of “best practices” that will both help use Tabnine better as well as have a few knock on benefits for any individual developer and the companies that they work for. So let’s dive in.
The heart of Tabnine is the machine learning (ML) algorithm that works in real-time to provide suggestions in the user’s IDE. Any ML algorithm is only as good as the data that was used to train it. Perhaps you remember the classic Cat OR Not? algorithm that was used to determine if a picture was that of a cat or something else. In order to successfully determine the animal in the picture, the algorithm was trained on millions of pictures of cats and not-cats from the internet. Tabnine’s code algorithms work very similarly. If you’d like to train an algorithm to help understand and suggest code for a Javascript front-end it would need to be trained on good Javascript doing front-end work. Tabnine comes configured with a large universal model that has been trained with billions of lines of open source code and specialized models trained for specific languages like Java, Typescript, Python and others.
For most users simply letting Tabnine handle the model switching gives users a great experience. Most developers get good completions with automatically switching models for various languages. As code complexity and variety increases there is an opportunity to boost productivity by pursuing a custom model solution. This is something that Tabnine can help with as well.
While the nuances of training large language models and custom derivations of these models isn’t specifically part of this article, a basic understanding of how these models learn is really helpful. The model will only really be able to suggest completions that it has observed in the training data. We call Tabnine an AI pair programming tool for a very good reason.
Imagine two developers working together side by side. The junior dev will want and appreciate the help of the senior engineer, but in this relationship communication is key to good results. Your AI pair programming buddy isn’t a mind reader and neither is Tabnine (though we are working on that in a few sprints…) To get the most out of a pair programming effort, as well as Tabnine we need to prompt the effort with comments and well thought through variable and function names.
Let’s look at a quick example:
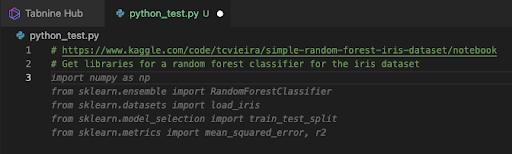
Figure 1: Here is an example of giving Tabnine some “meat” to work with in the comments. In this example we are creating an algorithm for the industry standard image classification problem using pictures of iris flowers. The url for the example is placed above for reference, and we lead with the task we wish to accomplish. In this case it’s acquiring the necessary libraries for a random forest classifier and manipulations of the dataset. The gray italics after the comment are the suggestions that Tabnine displays. We simply press the tab key to accept.

Figure 2: In this example the same outcome is attempted without the comments. While Tabnine will help complete individual lines (e.g. “import numpy as”…will get an autocomplete “np”) but as we can see the snippet completions are much shorter as the context and intention are not as clear.
Tabnine is contextually aware, and as a particular file grows in size Tabnine will understand variables and functions used previously, so that will certainly help, but there is so much more power available when we interact in a conversational manner. But beyond the help it gives the individual developer, there is more benefit for the developer and the customer or business they are working for. No pull request has been rejected for being too well commented. Tabnine helps reduce technical debt and bug work by helping build robust documentation for the code that is being written. And that is certainly something that will help everyone.
Altering your coding style to incorporate more comments and more conversational programming methods is what we have observed to be the key defining metric for our users that are really leveraging the tool for a meaningful productivity boost. Give it a try and see if it’s something that will work well for you as well.
Explore recent posts
//Explore recent posts
//
2 -min read

4 -min read

32 -min read

More How-to's
//3 -min read
4 -min read
5 -min read